

by Jamey Johnston, Sr. Data Scientist/Engineer, @STATCowboy
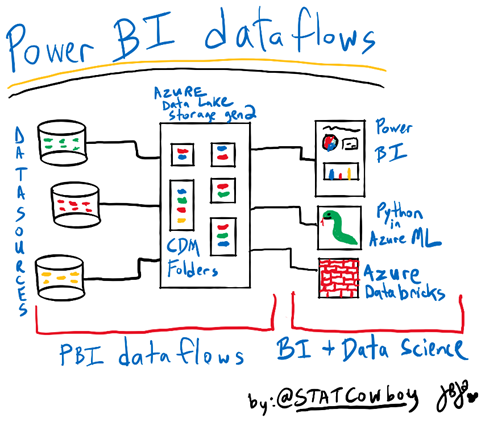
Why Power BI dataflows
Recently, I was reading an excellent article titled “Agile Digital Transformation for Data-Driven CEOs with Power BI” by Jen Stirrup (t|b) on why Power BI is a valuable tool for data driven CEOs to change the culture of their organizations. One of my favorite features to come to Power BI is Power BI dataflows and I believe it will improve the data management and usage in organizations. This article will discuss how dataflows can be used by BI professionals, data engineers and data scientist to improve their data management skills and build valuable insights for their companies.
I work with data scientist on a regular basis who spend a lot of time cobbling together data from different data sources to build models in Python using packages like Scikit-learn. These data scientist will often dump the data into CSV files and read them in as Panda dataframes or NumPy arrays to start the data science algorithm magic. This is messy! The data scientist often ask for new dumps of the data or losing the data dumps they have. I believe Power BI dataflows can really assist to make data management better for BI professionals, data scientist and data engineers.
What is Power BI dataflows
Power BI dataflows enable organizations to wrangle data spread across multiple data sources in the cloud or on-premises into Azure Data Lake Storage gen 2 in a Common Data Model. Dataflows are created and managed in workspaces in the Power BI service via an online version of the well-known Power Query interface. Data in Power BI dataflows can be leveraged by data scientist and data engineers in Azure services like Machine Learning (ML), Databricks and Azure Synapse Analytics because the data is stored in Common Data Model in Azure Data Lake Storage gen 2. Citizen Data scientist can take advantage of Microsoft Cognitive services or Azure Automated ML in dataflows. Microsoft also has Python packages like the Azure Datalake service client library for Python to connect to Azure Data Lake Storage gen 2 which can be used to connect to Power BI dataflows data to build data models in packages like Scikit-learn. Power BI reports can also connect to Power BI dataflows to build reports and dashboards.
Power BI dataflows Demo
Let’s look at Power BI dataflows. I have uploaded a CSV file of the Ames Housing Data
from Kaggle on my GitHub in a repository, https://github.com/STATCowboy/pbidataflowstalk, for Power BI dataflows.
To use Power BI dataflows you will need a Pro license of Power BI and to use some of the advanced features, like Cognitive Services or Automated ML, you will need Premium capacity. Your Power BI tenant admin and Azure admin will have to enable dataflows and connect to a Azure Data Lake Storage gen 2 to use the Power BI dataflows and integration with Azure Data Lake.
Once Power BI dataflows is setup, connect to your Power BI Service and create a workspace called “Ames Housing” and enable dataflows (under Advanced at the bottom) for the workspace.
Note, the Power BI service will manage the ACL (permissions) in the Azure Data Lake storage utilizing the users defined in the workspace automatically.
Now let’s import the CSV file of the Ames Housing data using dataflows. In your Ames Housing workspace click the “+Create” at the top and choose “Dataflow”.
Click the “Add new entities” button on the left panel on the page to open Power Query online to add the data.
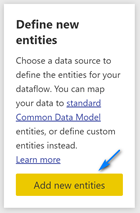
In the Power Query Online screen click “Text/CSV” button to add the Ames Housing data into dataflows.

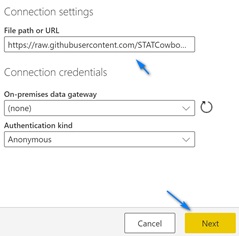
In the File path or URL textbox enter “https://raw.githubusercontent.com/STATCowboy/pbidataflowstalk/master/AmesHousing.csv” and then click the yellow “Next” button at the bottom right. Notice, you can connect to your On-premises data gateway if you have on-premises data.
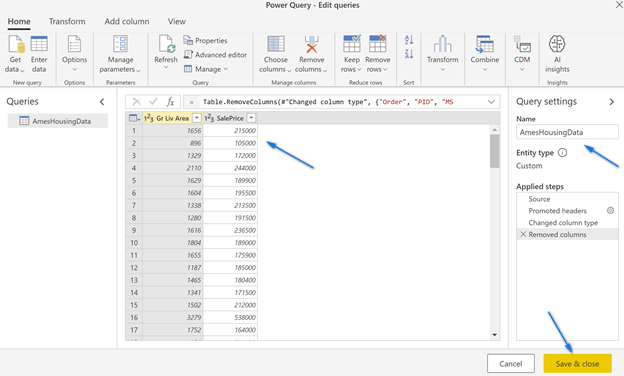
In the Power Query Online editor remove all the columns except, “Gr Living Area” and “SalesPrice”, name the table “AmesHousingData” and click “Save and close”.
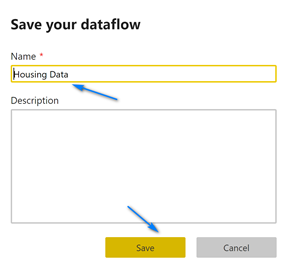
The next screen that pop-up is where we name our dataflow. Name your dataflow “Housing Data” and click “Save”. When it finishes saving click the “Refresh Now” button to populate your dataflow with data. Note, you can setup scheduled refreshes in dataflows including incremental refreshes.
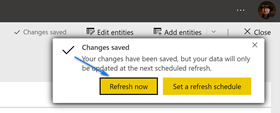
You should have data in your dataflow stored in your Azure data lake now!
Power BI Desktop
Now that we have data in our dataflow let’s connect to it using Power BI desktop.
Open Power BI Desktop and click the “Get Data” button at the top or on the startup screen.
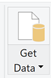
Select “Power Platform” on the left, then “Power BI dataflows” on the right and click “Connect”.
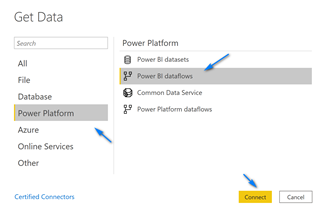
If this is the first time connecting to dataflows you will need to click the “Sign In” button and login to your Power BI Service. Once you login click “Connect”.
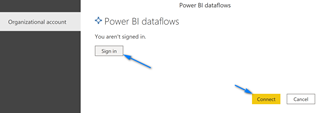
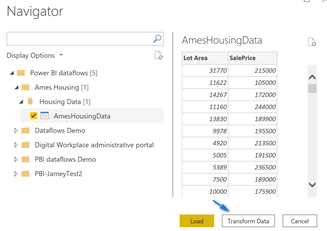
Once you are connected navigate to the “AmesHousingData” table and select it and click “Transform Data” or “Load” if you want and you will now have your Power BI dataflows data in Power BI Desktop to work with!
CDM Folders and Azure Data Lake Storage gen 2 (ADLS gen 2)
As mentioned earlier you can connect your Power BI dataflows to your own Azure Data Lake Storage and use it for data science or data engineering. The great thing that Microsoft did with Power BI dataflows is deploy the data into the Common Data Model in folders in Azure Data Lake Storage gen 2.
CDM Folders conform to “specific, well-defined, and standardized metadata structures and self-describing data. These folders facilitate metadata discovery and interoperability between data producers and data consumers”. (https://docs.microsoft.com/en-us/common-data-model/data-lake)
If you look at the diagram below it shows the layout of the “Ames Housing” workspace and “Housing Data” CDM folder after it was written to the ADLS gen 2 storage. On the left is the view from Storage Explorer and on the right is the diagram of a CDM folder from the Microsoft Power BI dataflows documentation.
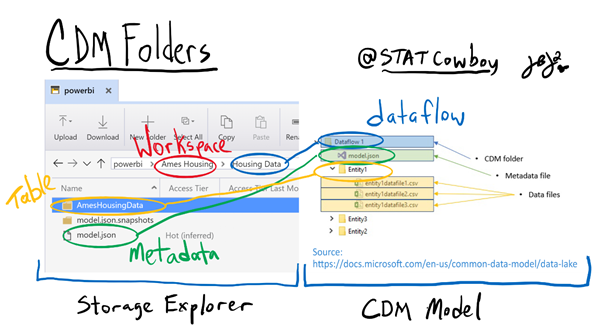
Storage Explorer
https://azure.microsoft.com/en-us/features/storage-explorer/
Python Demo to read CDM Folder for Data Science
Now that you have your data in ADLS gen 2 you begin to do the data magic! The azure-storage-file-datalake package was recently released to access hierarchical namespace enabled (HNS) ADLS gen 2 accounts. The below referenced Python demo will use this new package to access the CDM folders written by Power BI dataflows. It will also use the CDM helper file located here.
To run the demo follow the instructions here to setup a Conda environment using the below referenced YAML file to run the Python Demo below. Edit the Credentials.py file and update the accountName and credential variables to your values. Then run the AMES CDM Access Demo – Azure ML Python.py file to pull the data from entity, AmesHousingData, from the Ames Housing/Housing Data dataflow and run a simple OLS Linear Regression to predict SalesPrice from Gr Liv Area. You can run this in Visual Studio Code or Azure ML or any tool that can run Python like Jupyter Notebooks.
YAML file for Python Env
https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html#creating-an-environment-from-an-environment-yml-file
Python Demo
https://github.com/STATCowboy/pbidataflowstalk/tree/master/Azure%20ML%20Python%20Example
CDM Helper
https://github.com/Azure-Samples/cdm-azure-data-services-integration/tree/master/AzureMachineLearning
Databricks Demo to read CDM Folder for Data Science
You can also access the data in powerful tools like Azure Databricks. Follow the instructions on this GitHub, by Ted Malone (t|b) to configure you Databricks to access your Power BI dataflows in CDM Folders.
Databricks Setup
https://github.com/temalo/spark-cdm/blob/master/docs/Getting%20Started.md.
Sample code to connect to the Ames Housing Data you loaded in your Power BI dataflows in the demo above is in my GitHub.
Sample Code
https://github.com/STATCowboy/pbidataflowstalk/tree/master/Databricks%20Example.
Conclusion
I hope this article helped to introduce and showcase some of the great features of Power BI dataflows. To learn more about Power BI dataflows check out the official Microsoft documentation here. Also, I recommend following Matthew Roche (t|b) who works for Microsoft and evangelizes Power BI dataflows. Finally, follow me on Twitter @STATCowboy, connect up with me on LinkedIn at https://www.linkedin.com/in/jameyj/ or check out my blog, https://www.statcowboy.com to keep in touch.
GitHub Repo of Code
https://github.com/STATCowboy/pbidataflowstalk
Great stuff!